Hello and welcome to my first blog about HUUS - a storage engine. The inspiration came from a talk that I attended about a storage engine called magma.
A storage engine is the part of a database that deals with searching, retrieval and manipulation of data. It is the core component of the database, that deals with data.
The talk spoke about two algorithms to store data called LSM trees and B-trees. Magma itself was based on LSM trees and optimization to the way LSM Trees work themselves. However the talk spoke little about B-trees, which piqued my interest, hence HUUS was born.
Before proceeding, I recommend reviewing the B-tree algorithm, as it isn’t explained in detail here
Index
- Building the storage engine
- The persistent storage - HUUS
- Query parser - lychee
- Wrapping up
Building the storage engine
The first step to building this storage engine was building a toy implementation. It involved:
- Constructing the B-Tree algorithm
- implementing CRUD operations over this tree
B-Tree
The B-Tree algorithm used here is specifically a B+Tree algorithm, This variant is optimized for range searches, something that a simple B-Tree lacks.
Note: the B-Tree algorithm mentioned in this blog refers to the B+Tree variant
Node structure
type Node struct{
kvStore []KV
children []*Node
isLeaf bool
nextLeaf *Node
}
The node is structured as shown above. The kvStore (key-value store) contains the key-value pairs. The values in the intermediate nodes are not valid, it is only the leaf nodes that store the actual values, thus satisfying the B-Tree property.
Pre-emptive splitting/merging
The insertion and deletion were an interesting problem. The way it is implemented in HUUS is by preemptively splitting and merging the nodes (basically a top-down approach). This prevents the need to propagate splits/merges upwards.
 the tree has a order of 5 (max 4 keys in one node), here we see that even though the root node is not full, so normally we would not split it, however we pre-emptively split it assuming that it might become full if a new key is added to it. After the split is when we insert 90
the tree has a order of 5 (max 4 keys in one node), here we see that even though the root node is not full, so normally we would not split it, however we pre-emptively split it assuming that it might become full if a new key is added to it. After the split is when we insert 90
An insertion may cause a split at the leaf that bubbles up to the root
root->parent->leaf (insertion happens here)
The split now propagates from
leaf->parent->root
However a top down approach will avoid this by pre-splitting on the way down to the leaf.
An interesting point to note here, pre-splitting like this causes none of the nodes to ever be full (the maximum number of keys in any node will have m-2 keys at any time) apart from the root node. This is because when we encounter a node that might become full due to an insert we split it (this means splits occur when there are m-2 keys).
Once this tree is defined I can define methods over the tree to perform CRUD operations. This essentially creates an in-memory kv-store.
The next step is to make data durable - Persistence.
The persistent storage
Persistence is nothing but durable storage, this means data is retained even after a restart. The following are few steps that were necessary to go from an in-memory implementation towards a persistent implementation.
Paging and Encoding
- Paging : A page is a block of fixed-size memory that can be stored directly in memory. Databases read/write in fixed blocks for efficiency.
- Encoding & Decoding : This corresponds to converting node data into byte data and vice versa. This byte data is split into multiple pages and stored.

Node structure in HUUS
type node struct {
id uint32
parentId uint32
key [][]byte
pointers []*pointer
isLeaf bool
sibling uint32
}
the pointer object can point to:
- Value if the node is a leaf
- Child ID if the node is not a leaf
This node is what is updated in memory. When being converted into pages, it uses the encoding module to move from a node to a byte array. This byte array is then split between multiple pages and written into the file.
If one node spans many pages, even small changes force multiple page writes → more random I/O.
A future prospect is also to switch to slotted paging. It deals with the issues of operations being expensive in a flat layout. Data needs to be shifted in a flat layout, slotted paging deals with this by packing data more efficiently.
Metadata
This information needs to be stored so that the tree can be rebuilt on startup
type treeMetaData struct {
order uint16
rootId uint32
pageSize uint16
}
Tracking the parent node
First, why track the parent? When a split or merge occurs, a key travels between parent and child. Hence there is a requirement to track it, the alternative is to traverse from the root to find the parent again.
However storing the parentID in a durable storage is a bad idea.
Here is an example:
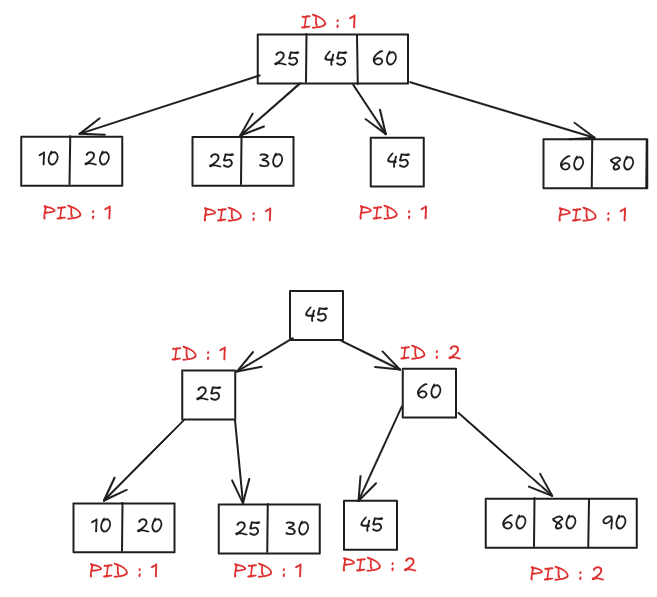 Here we see that the 2 child nodes of
Here we see that the 2 child nodes of nodeID=2 needs their parent id to be updated to 2 which is okay here its only 2 nodes, however with a tree of higher order it can even be 250-500 nodes that need to be updated.
This is handled using a technique called breadcrumbing. A stack is used to keep track of the nodes accessed. This works because backtracking occurs only during a single insert or delete, so the path can be stored temporarily.
new node encountered -> push into stack backtracking -> pop from stack
The storage module
This is the abstraction that interfaces between in-memory and durable storage. It enables persistence. It keeps track of page size, the last allocated page ID, and custom tree metadata (e.g., root node location).
With the components built and integrated, a simple and durable storage system based on the B-Tree algorithm was ready.
Putting it all together
I was then one step closer to building what’s called a storage engine. Here’s what I implemented:
- B-Tree Algorithm basic algorithm for insert, delete, and search.
- Persistence layer (paging + encoding) makes sure data is durable.
- Metadata ensures the tree can be rebuilt.
- Breadcrumbing removes the need for explicit parent tracking.
- Storage module bridges memory and disk.
Another small component apart from this was a query parser.
Lychee the Parser
To perform CRUD operations interactively, there needs to be something SQL-like. Lychee is meant for this purpose, it is a parser for queries. The queries are converted into API calls to interact with the storage engine essentially providing a run-time environment.
Here’s a quick example of the supported queries.
Using tree: example.db
lychee> INSERT(1,1)
Inserted successfully
lychee> READ(1)
Key:1, Value:[0 0 0 0 0 0 0 1]
lychee> DELETE(1)
Deleted successfully
It also supports two utility commands:
lychee> PRINT
Level 0: { 1 keys : [[0 0 0 0 0 0 0 1]] Values : [ [0 0 0 0 0 0 0 1] ] true 0 }
lychee> EXIT
Exiting
Wrapping up
HUUS started as a curiosity project to understand B-Trees better, but it has slowly evolved into a foundation for building a complete storage engine. What I’ve covered here are just the first building blocks.
My goal with HUUS isn’t just to create another storage engine, but to learn and document the journey of building one from the ground up.
This is only part one of the story, but I hope it gave you a glimpse into how databases work beneath the surface.
HUUS is open source, so go explore it: https://github.com/tejas-techstack/huus
If you want to see B-Trees in action, I recommend B-Tree Visualization.